





arghhhh, what to do when the file becomes corrupted!
One of the students here at Cranfield University, suffered a recent misfortune of corrupting a MS Word docx file. The file had been 30+ pages of closely written text, ready for a thesis meeting, when disaster struck. Somehow the document became corrupted and opened as a blank document with no text. Inspecting it, we realised the document size was still 1.5Mb – so the text was probably still in the file – even if we couldn’t see it.
We tried all means of tricks to cajole Word to open the file and recover the precious text, all to no avail. At a point frankly of some desparation, we remembered the docx file format is a zipped XML structure file. This is a saving grace – the earlier ‘doc’ format was just a proprietary binary format, now the ‘docx’ format offered some hope.
We took a copy of the file, and renamed it ‘document.zip’. This allowed us to open the zip archive, and to see the contents. Immediately we see the hierarchical structure of the document and the multiple files it contains.
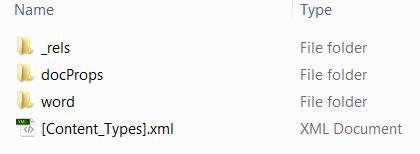 We could then open the folder ‘word’, which showed the principle contents of the document.
We could then open the folder ‘word’, which showed the principle contents of the document.
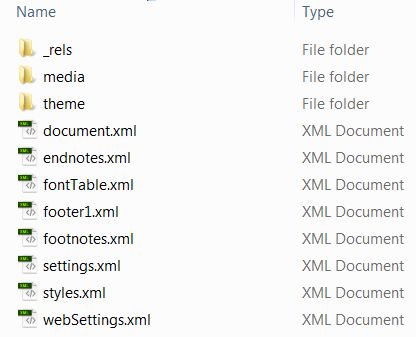 Straight away, we can see the sub-folder ‘media’ – this folder contained all the images that had been in the original document. Great – those were saved off. Now we needed to extract the text itself.
There is also the key file ‘document.xml’ – XML is XML is a software- and hardware-independent tool for storing and transporting data (http://www.w3schools.com/xml/xml_whatis.asp), stored in plain text. We extracted the text and loaded in our favourite text editor (TextWrangler – for the Mac). Inspecting the XML file shows the usual structures of xml – all spun onto a single line, thus:
Straight away, we can see the sub-folder ‘media’ – this folder contained all the images that had been in the original document. Great – those were saved off. Now we needed to extract the text itself.
There is also the key file ‘document.xml’ – XML is XML is a software- and hardware-independent tool for storing and transporting data (http://www.w3schools.com/xml/xml_whatis.asp), stored in plain text. We extracted the text and loaded in our favourite text editor (TextWrangler – for the Mac). Inspecting the XML file shows the usual structures of xml – all spun onto a single line, thus:
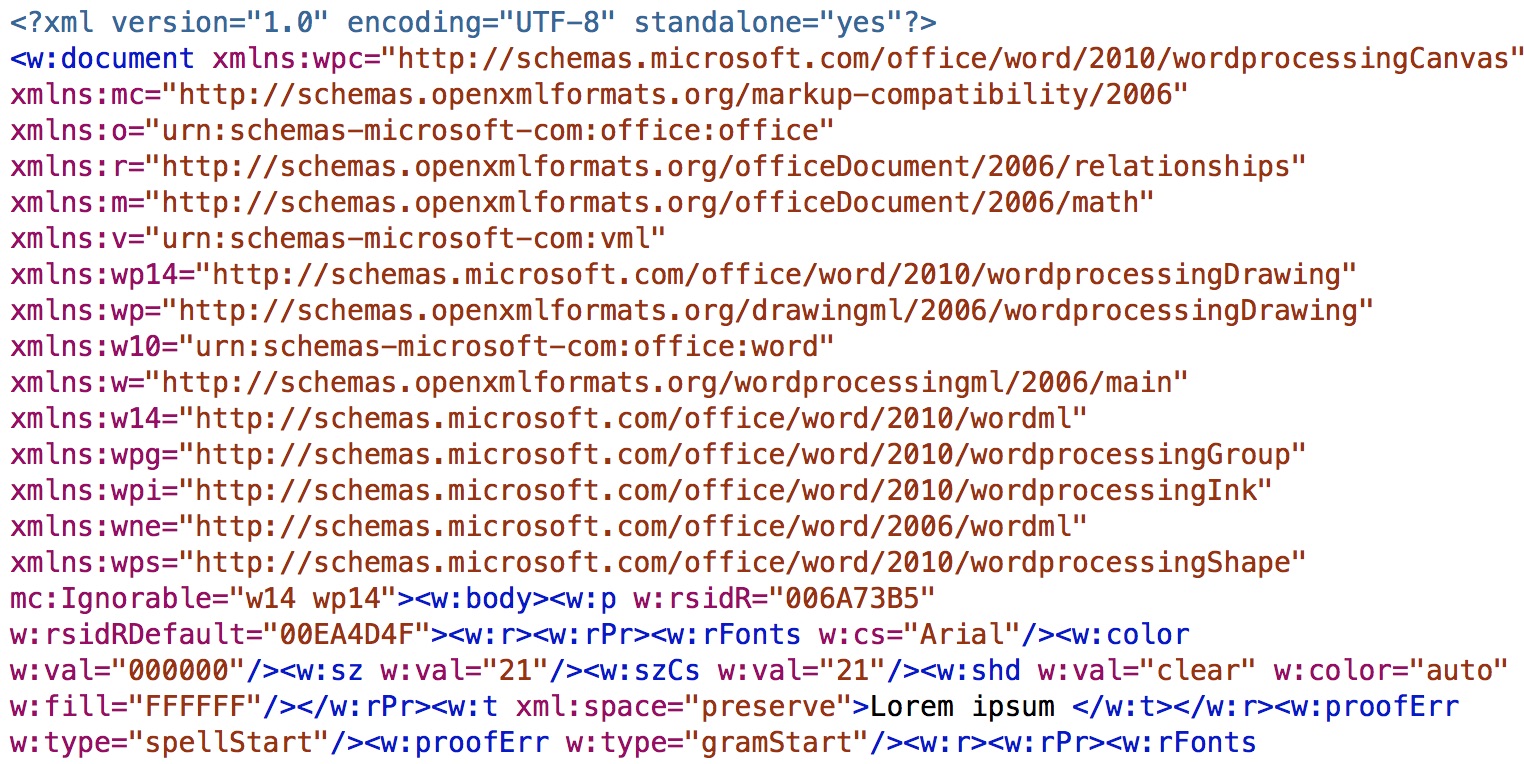 We could then hunt through the file and locate the text in the XML, noting the tags within which the text was recorded. In this case, we can see text tagged with
We could then hunt through the file and locate the text in the XML, noting the tags within which the text was recorded. In this case, we can see text tagged with <w:t>.
 So now we needed an automated method to extract all the text from the document – to start with, no such tool is present on the Mac. However, thanks to Kevin Peck’s excellent blog here (http://kevsaidwhat.blogspot.co.uk/2013/03/other-mac-things-i-have-learned.html) we found that the software xml_grep did exactly what we wanted. This uses the module XML::Twig for Perl (http://www.xmltwig.org/xmltwig/). Perl is a fantastic scripting language – well worth learning, and excellent for file manipulation.
As Kevin notes, the tool was swiftly installed in the Mac thus:
So now we needed an automated method to extract all the text from the document – to start with, no such tool is present on the Mac. However, thanks to Kevin Peck’s excellent blog here (http://kevsaidwhat.blogspot.co.uk/2013/03/other-mac-things-i-have-learned.html) we found that the software xml_grep did exactly what we wanted. This uses the module XML::Twig for Perl (http://www.xmltwig.org/xmltwig/). Perl is a fantastic scripting language – well worth learning, and excellent for file manipulation.
As Kevin notes, the tool was swiftly installed in the Mac thus:
cd XML-Twig-3.50 (use latest version downloaded here)
perl Makefile.PL -y
make
make test
sudo make install
Once the tool was built and working, we could run the extraction we wanted, thus:
$> xml_grep --text_only --cond 'w:t' document.xml > extractedtext.txt
This produced a file holding the text of the document – which at least allowed our student to carry on with their work – albeit that the report needed reconstructing. Also it was interesting to see how the Office files are held as zipped XML format. In any case – phew! The learning point in all this of course is the BACK UP YOUR FILES!! This has of course been said many times ;)]]>
Cranfield University GeoThread Blog
